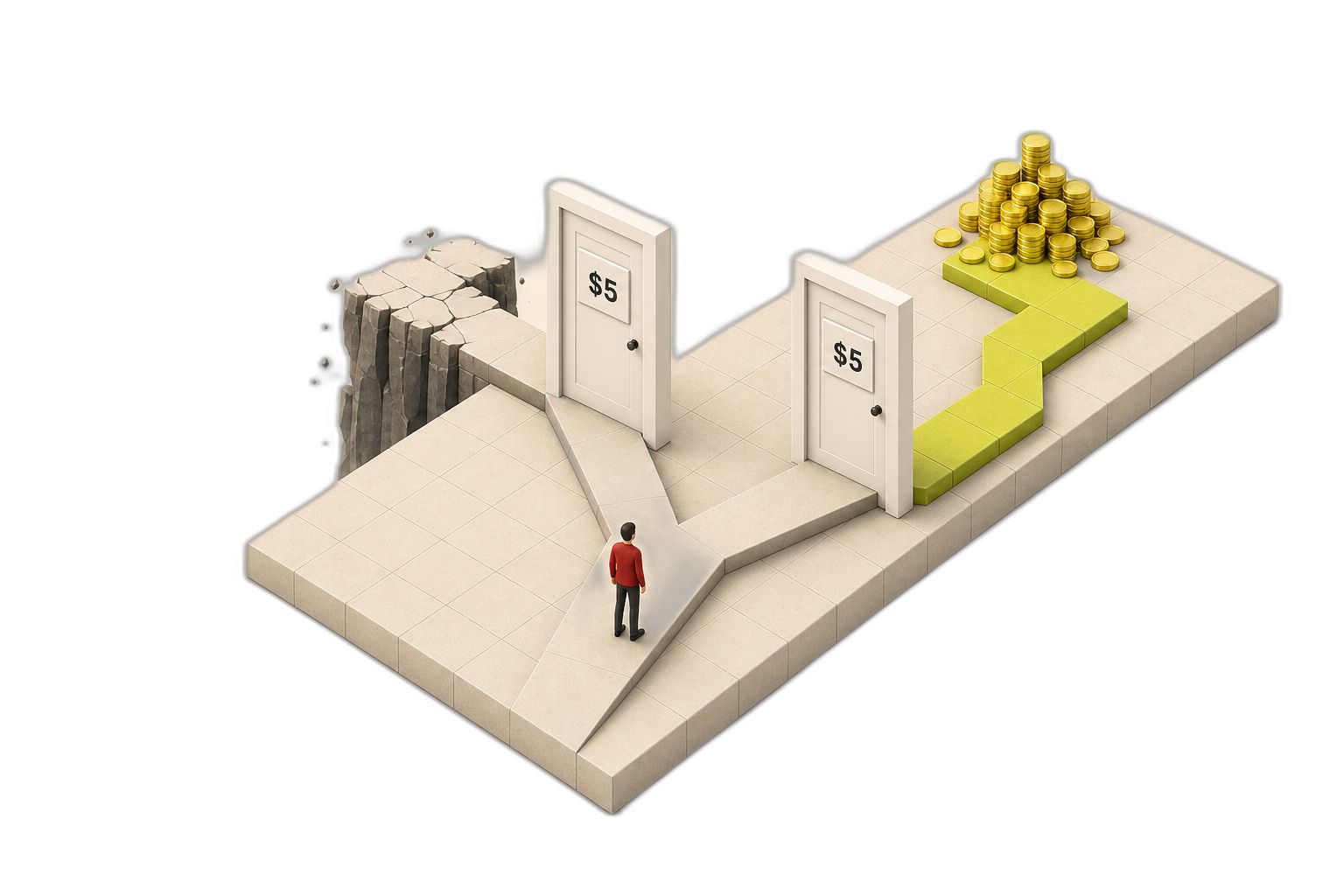
Maria's card was charged twice. She messaged support, the AI apologized, issued a full refund, and closed the ticket. A perfect resolution.
Three weeks later, Maria cancelled.
The AI logged RESOLVED. The business saw CHURNED. A double charge is not a billing error. It is a trust emergency, and the model had no way to know, because everything it is trained to optimize ends the moment the session does.
Look at what today's models are actually rewarded on. Thumbs up. Ticket closed. Clause accepted. Tests passed. Every one of these is a session-level proxy, available immediately, and every one of them can diverge from the outcome the business gets weeks later. Retention. Revenue. Renewal. The real reward exists, but it lives in your data warehouse, long after the training signal has been collected and consumed.
Reinforcement learning is only as good as its reward function, and session-level rewards get hacked. The cheapest way to earn a thumbs up is to agree with the user. OpenAI shipped a ChatGPT update optimized on short-term user feedback and rolled it back within four days because the model had turned sycophantic. That was not RLHF malfunctioning. That was RLHF executing perfectly, on a bad brief.
Every LLM in production today is optimized like a sugar rush. The model learns what feels good in the moment. The bill arrives later, and nothing in the training loop ever sees it.
Ad platforms are an AI deciding where billions in spend go. Their bidders are the most sophisticated prediction machines ever pointed at human behaviour, and they share the same blind spot: everything they learn from ends shortly after the click. The renewal in week six, the repeat order in month three, the annual subscriber compounding quietly against the weekly churner who looked identical on day one. All of it lands on your side of the fence, after the optimization window has closed.
The machine does not fail. It succeeds brilliantly at the wrong target. Ask for trial starters and it finds trial starters with terrifying efficiency, including the ones who never pay.
For three years Churney has engineered the signal those platforms were missing: predicted long-term value, causally corrected, shaped into the exact form a black-box learner can digest. Hundreds of data warehouses connected, hundreds of millions in spend influenced, in a market that moves $650B a year. Zapier saw a 190% ROAS improvement on Meta when our signal replaced their in-house one. Across our portfolio, the pattern holds at around 30% lift in long-term ROI.
LLMs have the same shape. A learner rewarded on what it can see, a truth that arrives weeks later, and a business paying the difference. Same problem, new machine.
Here is what changed this year. Reinforcement fine-tuning has launched across the major platforms. Vertex AI offers RFT, OpenAI offers DPO and reward-based training, Anthropic models can be tuned through Bedrock. Different names, same interface: a prompt, a response, and a score. For the first time, you can fine-tune a frontier model toward a number of your choosing.
Which makes the score the whole game. Send a naive metric and the model reward-hacks it. Send human preferences and you get sycophancy back. Send short-term conversion and you optimize the sugar rush with extra steps.
The missing input is a predicted long-term outcome score, engineered so the model cannot game it. That is the reward layer, and it is what we build.
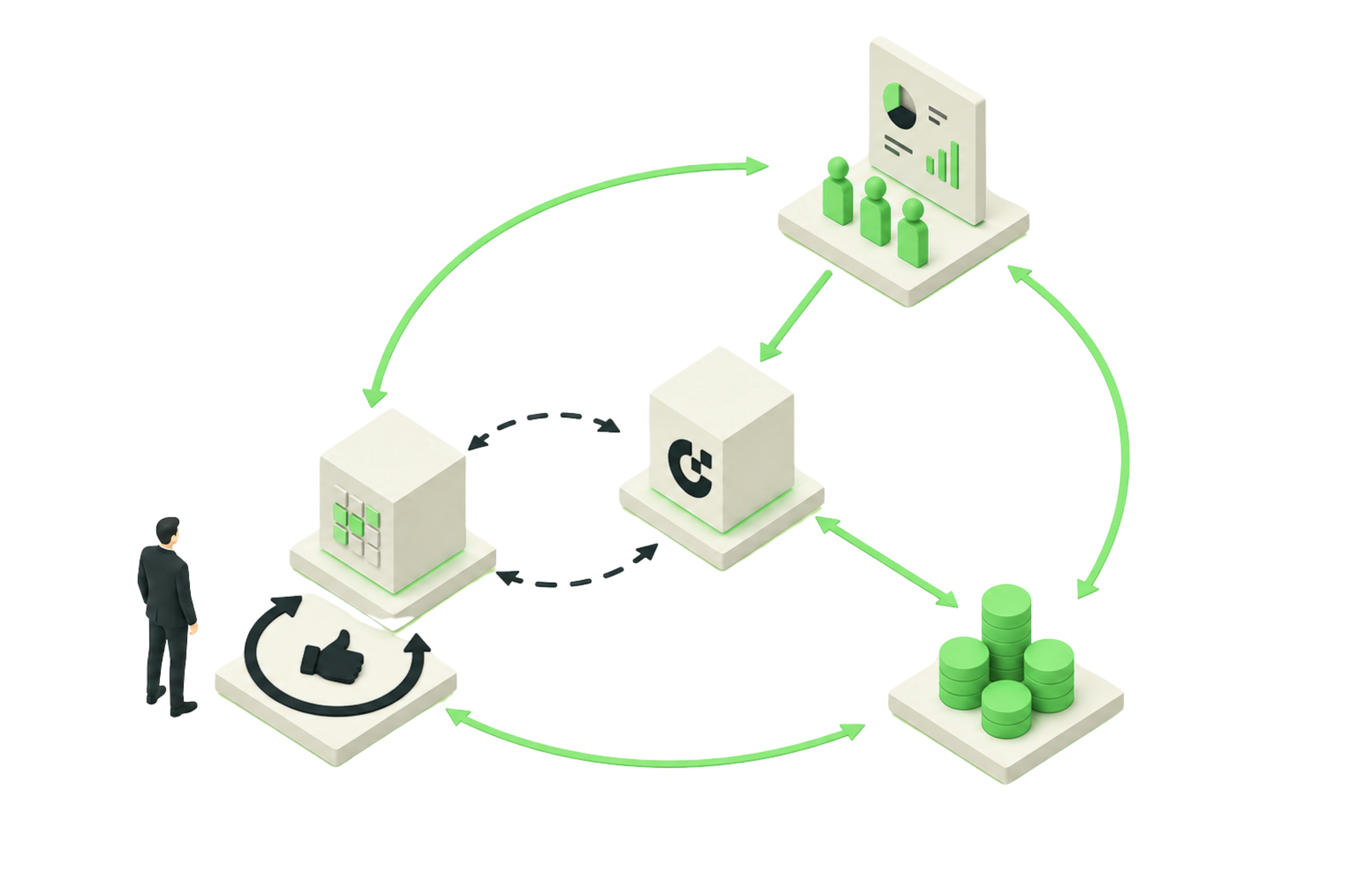
The loop has four steps, and it never stops running.
In Maria's case, the loop scores that perfect resolution as a loss, because she churned. The next double charge gets a response that recovers the customer instead of just refunding the charge.
Chess is the cleanest testbed for a reward, because ground truth is not up for debate.
We took Gemini 2.5 Flash, cheap and off the shelf, and fine-tuned it on a reward we engineered ourselves: every move scored by engine evaluation in centipawns, normalized, with material balance as the leading indicator. No prompt tricks. No bigger model. Just a better reward.
The result: 2x move accuracy, roughly 1,500 Elo from near zero, at a fifth of the cost. On a third-party LLM chess leaderboard we do not run, the fine-tuned Flash model beats the frontier model it is five times cheaper than.
The reward beat the prompt. It also beat scale.
Chess compresses into minutes what production stretches over weeks, so in production the loop runs at two speeds. The model acts now, on the best predictive signal available. When outcomes mature, we ingest them, correct the divergence, and feed it back. Append-only pipelines, recalibration when the mix shifts, holdouts so the lift is proven against a baseline instead of a dashboard. Delayed feedback is not a reason to skip outcome-based training. It is the reason the infrastructure has to be built for delay.
One requirement we state plainly: this needs outcome data. A clean warehouse, stable identity, and agreement on what ground truth means for your use case. The truth has to exist before anyone can train on it.
The current market for training signals sells human opinions. Labeled examples, ranked preferences, expert annotations. All of it point-in-time, and none of it measures what happened after. Opinions about what looks good are how we got sycophancy.
The next layer sells outcomes. Causal predictors of what actually worked, measured on live systems with real users and real money, fed back into models that are finally able to learn from them.
Every AI maker will eventually need a reward grounded in what actually happened. The fine-tuning endpoints are live, the models are hungry, and the truth is sitting unused in the warehouse. We built the layer that connects them.
Churney. The reward layer for AI.
We are presenting this work at RAISE Summit in Paris, July 8 and 9, as a top-10 finalist on the Backblaze track. If session-level success is not the same as business success in your product, find us there.
Every model is optimized for the moment it can see. The outcomes that matter arrive weeks later, in your data warehouse. Churney engineers the predictive reward signals that connect the two.