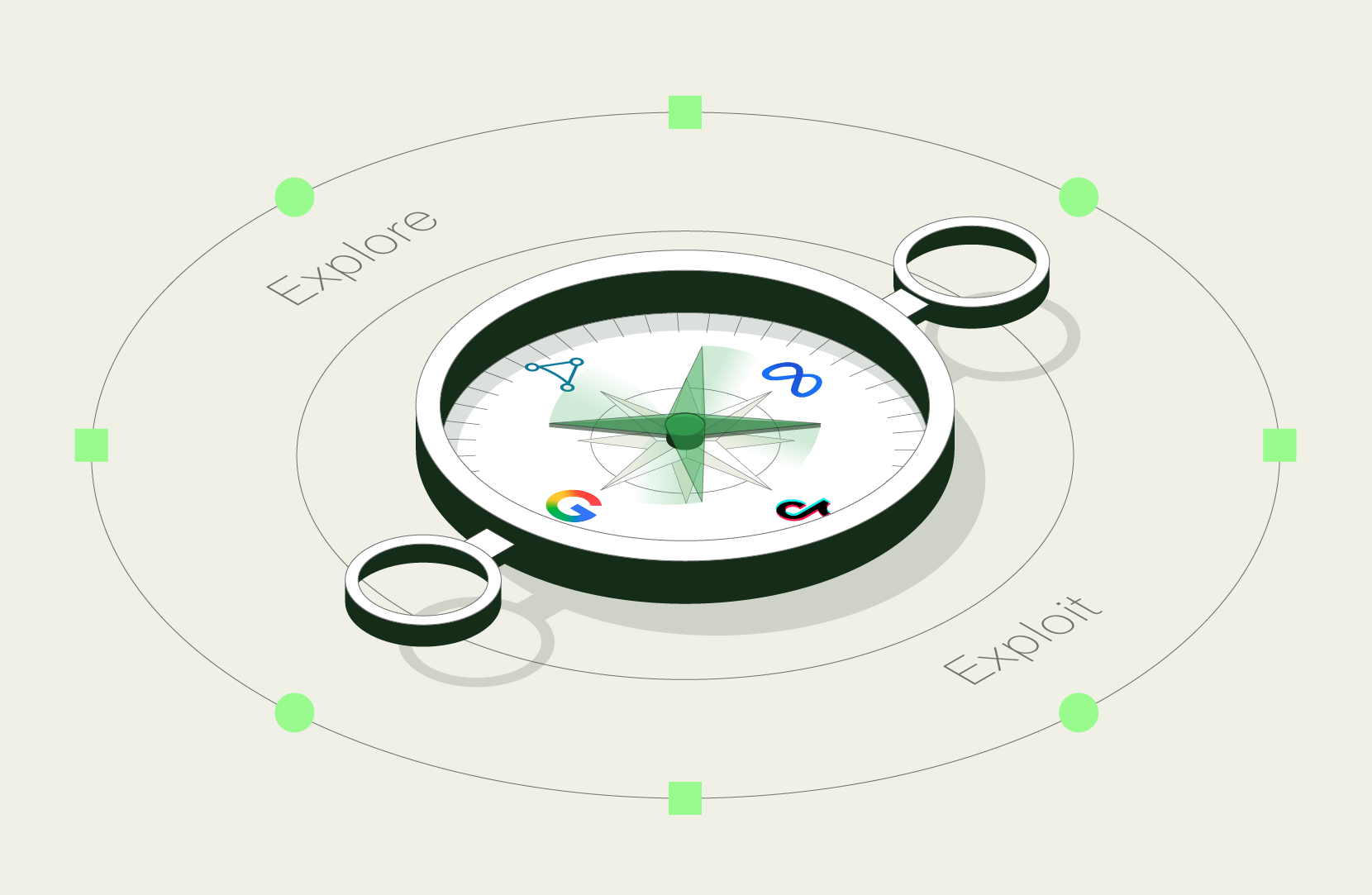
Every growth professional faces the same fundamental question: do we scale what's working, or test something new?
This isn't just a tactical dilemma. It's a mathematical one. If you've worked in growth or performance marketing, you've been solving multi-armed bandit problems all along, even if you didn't know it. Every decision (which channel to scale, which audience to target, which creative to invest in) is an instance of the exploration–exploitation trade-off, a concept that sits at the core of decision theory, reinforcement learning, and adaptive systems.
The multi-armed bandit (MAB) problem dates back to the 1930s. Picture a gambler facing several slot machines, each with an unknown payout rate. The gambler must decide which machine to play to maximize total winnings over time.
Each pull yields a reward and updates the gambler's understanding of that machine's true probability. The tension is constant: exploit what you know by sticking with the best-performing machine, or explore others to ensure you're not missing something better.
Exploit too much and you stagnate. Explore too much and you waste resources. Mathematicians discovered optimal strategies to minimize so-called regret, and these principles have become a cornerstone of machine learning.
Modern MAB algorithms formalize this balance in elegant ways:
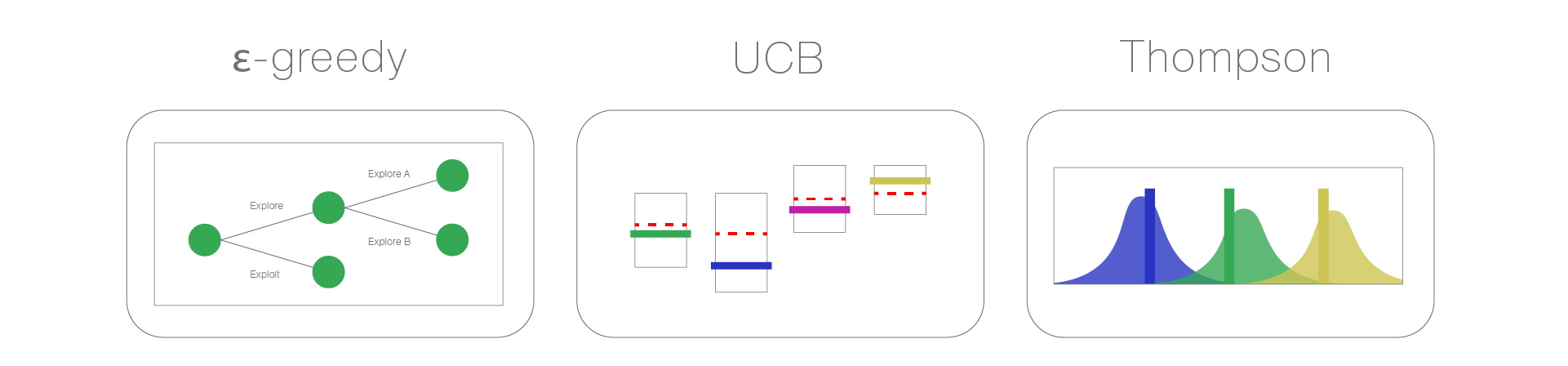
ε-greedy: Exploit the current best option 95% of the time; explore randomly the other 5%.
Upper Confidence Bound (UCB): Add a confidence term that favors options with high uncertainty (arms that might still surprise you).
Thompson Sampling: Instead of just tracking averages, you maintain a range of possible outcomes for each option. The algorithm randomly picks based on each option's likelihood of being the best. If an arm could be amazing, but you haven't tested it much, it gets more chances. As you gather data, the ranges narrow and the truly good options rise to the top.
In all cases, the system learns dynamically, reallocating attention and budget based on incoming evidence.
Sound familiar? This is exactly how modern growth operates.
Growth professionals live this tension daily, often without realizing it.
Exploit: Scale the top creative, the best-performing audience, the proven acquisition channel.
Explore: Test new messages, features, bidding strategies, or entire growth motions.
When a growth lead asks, "Should we put more budget into Meta or test TikTok?", she's performing Thompson Sampling. When a lifecycle marketer runs controlled experiments on retention flows before rolling one out broadly, that's UCB thinking. When a CMO allocates 80% of spend to predictable ROI campaigns while reserving 20% for moonshots, that's an ε-greedy policy. What computer scientists formalized in mathematics, marketers reinvented through practice.
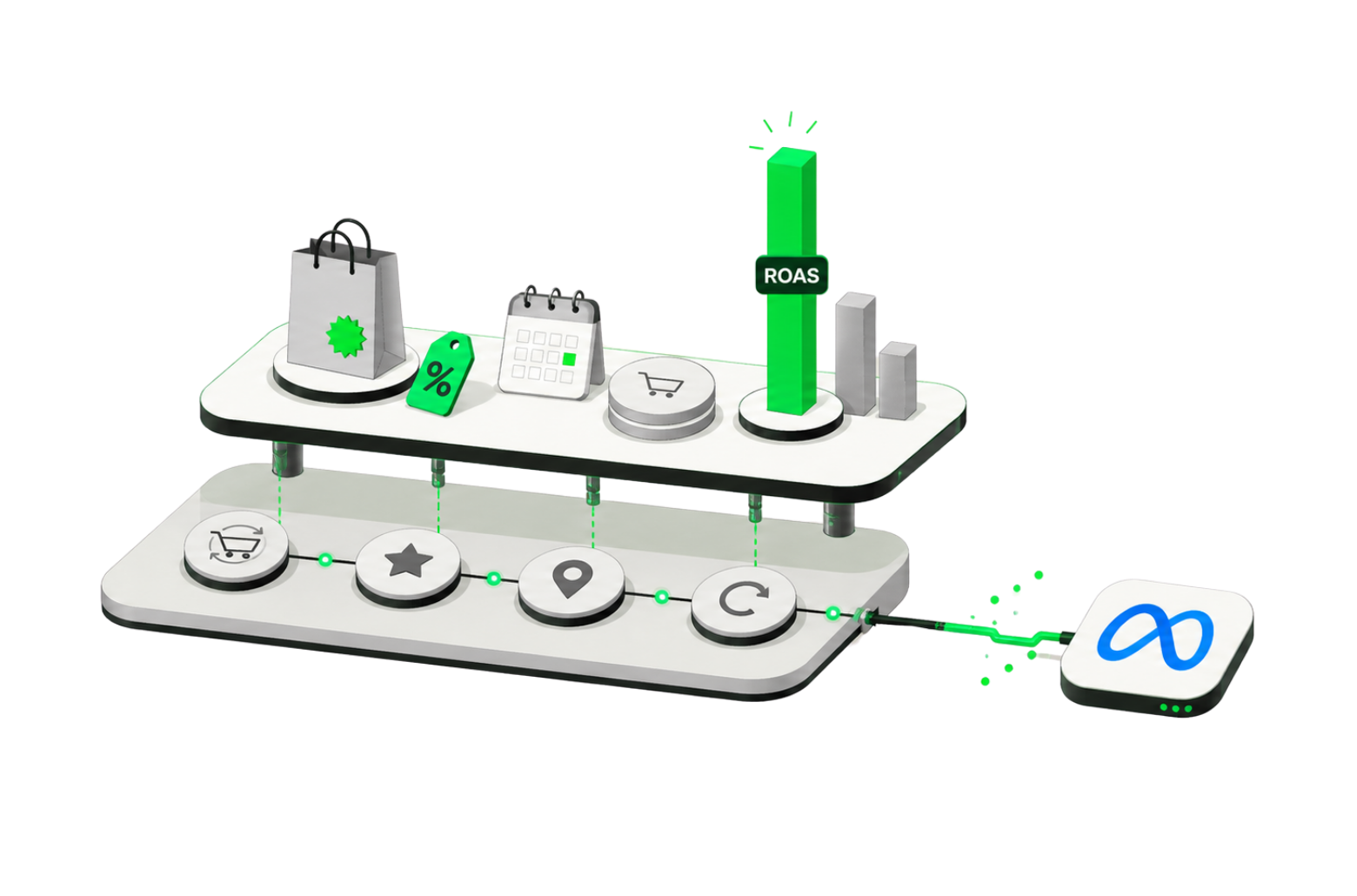
Consider a B2C app running paid acquisition on Meta with $500k in monthly spend.
Historically, most budget goes to CPA-optimized campaigns targeting cost per registration or first purchase. These campaigns exit Meta's learning phase quickly, but they optimize for short-term conversions rather than durable revenue.
tROAS campaigns, on the other hand, optimize for value-based events like purchases or in-app revenue. They often struggle to exit learning (especially with low event volume) and can stall before reaching statistical stability. At Churney, we recognize that both "arms" need testing, but not solely on short-term metrics.
Instead of optimizing tROAS for first-purchase value, we convert the target signal to Day-90 predicted long-term value (pLTV). Rather than locking onto a single event (like registration or purchase) that might not have enough volume for Meta to learn from, we build a signal that provides enough data for Meta to exit learning while still predicting long-term revenue.
The result isn't just "testing campaign types." It's testing which objective structure yields the best long-term ROI, using the same mathematical principles that power machine learning systems.
We also analyze how teaching Meta to optimize for long-term value differs from targeting immediate conversions. This lets us see not just which campaigns perform better, but how the platform's behavior changes when we feed it better signals. We're not just testing campaigns—we're testing how the platform learns from us.
This approach reflects something bigger.
Growth, marketing, and product have organically evolved to embody a 90-year-old mathematical principle. Growth isn't a collection of tactics. It's the human version of an adaptive learning system. It means experimenting under uncertainty, updating beliefs with new data, reallocating resources continuously, and optimizing not just for immediate returns but for long-term compounding outcomes.
At Churney, we make that intuition explicit. Our platform feeds ad systems with pLTV signals that automatically and continuously balance testing and scaling.
Because growth is too important to leave to intuition alone, and too human to automate entirely.